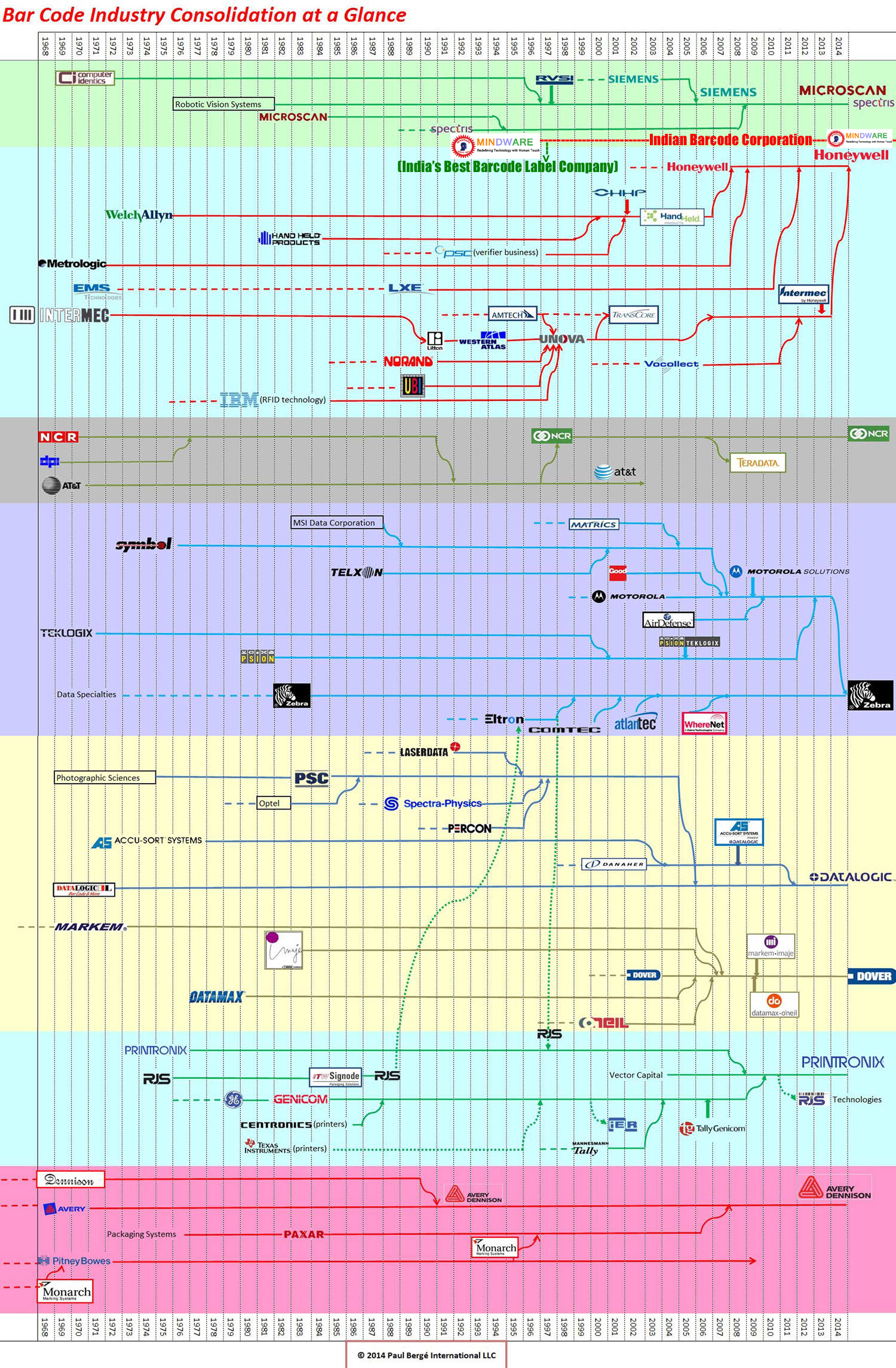
Promoters Of AIDC Community

Gulshan Marwah
CEO: MINDWARE (1996)

Gulshan Marwah
Owner: New Delhi Printers
Gulshan Marwah
Owner: Barcode Vault
Gulshan Marwah
CEO: MINDWARE (1996)
Gulshan Marwah
Owner: New Delhi Printers
Gulshan Marwah
Owner: Barcode Vault


Published on 10 Jun, 2019 | 03:50:03 PM
Share to:Linear or one-dimensional (1D)
There are many different types of One Dimensional Barcode.
This tutorial will show you many of the 1D Barcode Formats and will help you
understand the differences. A 1D barcode or One Dimensional Barcode is called
this because of how the barcode is read. A 1D barcode is read from side to
side. e.g. Code128, Code 39,
and UPC are referred to as Linear or
1D (one-dimensional) barcode symbologies.
1D
Barcode:
• Holds less than 85 characters (symbology
specific character limit).
• A majority of customers are set up to use
Linear barcodes (Linear scanner).
• Creates a wide barcode.
The main benefits of 1D barcodes in price. The barcode scanners for 1D barcodes are less expensive than the 2D barcode scanning is newer and thus more expensive. If your organization does not need a large amount of data is barcodes, 1D is the money-wise option. Another advantage is the overall performance of the 1D barcode scanner. Generally, it performs faster, has a longer scanning range, and lighting is irrelevant.
1D Barcode Types:
· CODABAR
· CODE 11
· CODE 25
· CODE 32 Italian Pharmacode
· CODE 39
· CODE 93
· CODE 128
· GS1 DATABAR
· EAN Code
· INTERLEAVED-TWO-OF-FIVE (ITF)
· MSI PLESSEY
· UPC Code
· KIX
· RM4SCC
Introduction of CODABAR
Codabar is a linear barcode symbology developed in 1972 by Pitney Bowes Corp. It was designed to be accurately read even when printed on dot-matrix printers for multi-part forms such as FedEx airbills and blood bank forms, where variants are still in use as of 2007. Although newer symbologies hold more information in a smaller space, Codabar has a large installed base in libraries. It is even possible to print Codabar codes using typewriter-like impact printers, which allows the creation of a large number of codes with consecutive numbers without having to use computer equipment. After each printed code, the printer's stamp is mechanically turned to the next number, as for example in mechanical mile counters.
Characteristics:
· This symbology is used by U.S. blood banks, photo labs, libraries, and FedEx airbills.
· Encodes numbers and the characters –$:/.+
· First and last symbols (the guard patterns) are one of A, B, C, or D. They are returned as part of the data string.
· Supports variable length data content.
· Some standards that use Codabar will define a check digit, but there is no agreed-upon standard checksum algorithm.
· The width ratio between narrow and wide can be chosen between 1:2.25 and 1:3.
Specification of Codabar:
Because Codabar is self-checking, most standards do not define a check digit. Some standards that use Codabar will define a check digit, but the algorithm is not universal. For purely numerical data, such as the library barcode pictured above, the Luhn algorithm is popular. When all 16 symbols are possible, a simple modulo-16 checksum is used. The values 10 through 19 are assigned to the symbols, respectively.
Code 11
Introduction of Code 11
Code 11 is a barcode symbology developed by Intermec in 1977. It is used primarily in telecommunications. The symbol can encode any length string consisting of the digits 0–9 and the dash character (-). A twelfth code represents the start/stop character, commonly printed as "*". One or two modulo-11 check digit(s) can be included.
It is a discrete, binary symbology where each digit consists of three bars and two spaces; a single narrow space separates consecutive symbols. The width of a digit is not fixed; three digits (0, 9 and -) have one wide element, while the others have two wide elements.
The valid codes have one wide bar, and may have one additional wide element (bar or space).
Characteristics:
· Primarily used for labeling telecommunication equipment. Also known as USD-8.
· The barcode data can be encoded numerical data, the dash and dot character.
· Supports variable length data content.
· For up to 10 data digits a single check digit is used, otherwise, two check digits are used.
Specification of Code 11
The decoding table has 15 entries because the symbols with two wide bars (1, 4 and 5) are listed twice.
Assuming narrow elements are one unit wide and wide elements are two units, the average digit is 7.8 units. This is better than codes with a larger repertoire like Codabar (10 units) or Code 39 (11 units), but not quite as good as Interleaved 2 of 5 (7 units). The non-binary symbology Code 128 uses 5.5 units per digit (11 units per digit pair).
Code 25
The Interleaved 2 of 5 barcodes is often an overlooked and yet important symbology used in the shipping and warehouse industries. Typically it is printed in low density to make it easy to scan or “read,†but it really is a high-density, numbers-only barcode developed in 1972 by David Allais, a leader in barcode design and the automatic identification industry. It goes by a variety of names including I 2 of 5, I/L 2 of 5, 2 of 5, 2/5 Interleaved and some more unique one like ANSI/AIM ITF-5, ANSI/AIM I-25, Uniform Symbology Spec ITF, and USS ITF 2/5, ITF.
One of the drawbacks of using this particular code is that it will only work with an even number of numeric characters. If there are an odd number of digits to encode, a zero is often added to the beginning of the code. Since the data security of Interleaved 2-of-5 is not quite as good as the popular alpha-numeric Code 39, adding a CheckSum or Digit would also work. Yet another way around this “pairs†requirement is to add five narrow spaces to the last digit.
Unlike other linear types of barcodes, the bars and spaces in Interleaved 2 of 5 only have two widths – wide and narrow. What makes it so popular is that the data will be encoded in both the bars AND the spaces between the bars, thus achieving higher density by taking half the space of a Code 39 barcode. It is called “interleaved†because the data is interleaved between the bars and spaces. For instance, the first character will use the first five bars, while the second character will use the first 5 spaces. By doing this, two characters are encoded in the space of what 5 bars would normally take. Two of every 5 bars or spaces are wide and three are narrow. This explains why this symbology will only accept an even number of characters. It also explains where the term “2 of 5†comes from.
Characteristics:
· Also known as Standard 2 of 5, Industrial 2 of 5 or Discrete 2 of 5.
· Legacy numerical barcode format with a low data density.
· Supports variable length data content.
· By default, no checksum is verified.
SDK Features: An optional mod10 checksum can be enforced.
Specification of Code 25
Unlike other barcodes, I 2 of 5 will often contain what are called “bearer bars†that create a frame around the entire code or simply two perpendicular bars running across the top and bottom of the code. It’s rather interesting to understand the history of those bars… the name “bearer bars†comes from the design of a metal grate or gate. Keep in mind too, that this code is commonly used on shipping boxes and the original way to print barcodes on cardboard involved stamping a printed image. In order to prevent barcode distortion when the stamp or print plate hits the box, bearer bars were added to strengthen the plate. Another solid incentive for using the bearers was discovered when people tried to scan the barcode at too sharp an angle. If that happens, the reader may not pick up all the data at the ends of the barcode and without realizing it, a valid translation will still be reported. The extra bars help prevent this from happening and also assure a proper quiet zone.
Another place where I/L 2 of 5 with bearer bars is popular is on security badge labels where space constraints are a concern. Time clock readers typically require barcodes up to 18 digits in length so the compressed interleaving or interweaving is particularly useful on labels less 3.00†long.
There is also an older, Standard 2 of 5 (aka Industrial 2 of 5 or simply 2 of 5) that has been around since the 1960s; it is used in photofinishing, on airline tickets and warehouse sorting. It is a fairly simple low-density code that encodes data only in the width of the bars, not the spaces. Because it can encode any number of characters and not just an even number of values, it can easily incorporate an optional module or mod 10 check digit to improve the accuracy of the symbology. Like Interleaved 2 of 5, the wide bars are typically three times the width of the narrow bars, but the spaces are usually the width of the narrow bar.
CODE 32
CODE 32 Italian Pharmacode
Pharmacode, also known as Pharmaceutical Binary Code, is a barcode standard, used in the pharmaceutical industry as a packing control system. It is designed to be readable despite printing errors. It can be printed in multiple colors as a check to ensure that the remainder of the packaging (which the pharmaceutical company must print to protect itself from legal liability) is correctly printed.
For best practice (better security), the code should always contain at least three bars and should always be a combination of both thick and thin bars, (all thick bars or all thin bars do not represent a secure code).
Characteristics:
· It encodes numeric data in a compressed format by using Code 39 – Regular character set.
· The symbol comprises the following elements:
· Eight symbol characters that represent numeric digits
· Check digit
· If fewer than eight characters are specified, padding characters are added.
· Code 32 uses five bars and four spaces to encode each character. Three of the elements are wide, and the other six are narrow.
· This symbology supports the following alphanumeric characters:
· All numeric digits (0-9)
· All uppercase letters except for A, E, I, and O
· The Code 32 human readable interpretation begins with the ASCII character “Aâ€. This character is not encoded into the barcode.
· Code 32 uses a check digit that is based on the modulo 10 (mod 10) algorithm.
Specification of CODE 32 Italian Pharmacode
Pharmacode can represent only a single integer from 3 to 131070. Unlike other commonly used one-dimensional barcode schemes, pharma code does not store the data in a form corresponding to the human-readable digits; the number is encoded in binary, rather than decimal. Pharmacode is read from right to left, also in left to right (if omnidirectional scanner): with as the bar position starting at 0 on the right, each narrow bar adds to the value and each wide bar adds. The minimum barcode is 2 bars and the maximum 16, so the smallest number that could be encoded is 3 (2 narrow bars) and the biggest is 131070 (16 wide bars). It represents colors that are on the label.
Code 39
Code 39 (also known as Alpha39, Code 3 of 9, Code 3/9, Type 39, USS Code 39, or USD-3) is a variable length, discrete barcode symbology.
Code 39 the specification defines 43 characters, consisting of uppercase letters (A through Z), numeric digits (0 through 9) and a number of special characters (-, ., $, /, +, %, and space). An additional character (denoted '*') is used for both start and stop delimiters. Each character is composed of nine elements: five bars and four spaces. Three of the nine elements in each character are wide (binary value 1), and six elements are narrow (binary value 0). The width ratio between narrow and wide is not critical and may be chosen between 1:2 and 1:3.
The barcode itself does not contain a check digit (in contrast to—for instance—Code 128), but it can be considered self-checking on the grounds that a single erroneously interpreted bar cannot generate another valid character. Possibly the most serious drawback of Code 39 is its low data density: It requires more space to encode data in Code 39 than, for example, in Code 128. This means that very small goods cannot be labeled with a Code 39 based barcode. However, Code 39 is still used by some postal services (although the Universal Postal Union recommends using Code 128 in all cases), and can be decoded with virtually any barcode reader. One advantage of Code 39 is that since there is no need to generate a check digit, it can easily be integrated into existing printing system by adding a barcode font to the system or printer and then printing the raw data in that font.
Code 39 was developed by Dr. David Allais and Ray Stevens of Intermec in 1974. Their original design included two wide bars and one wide space in each character, resulting in 40 possible characters. Setting aside one of these characters as a start and stop pattern left 39 characters, which was the origin of the name Code 39. Four punctuation characters were later added, using no wide bars and three wide spaces, expanding the character set to 43 characters.
Characteristics:
· Mostly used in logistics to encode application-specific identifiers.
· The standard version can encode numbers 0-9, capital letters A-Z, symbols -.$/+% and space.
· Supports variable length data content.
· Narrow to wide bar ratios from 1:2 up to 1:3 are supported. 1:2.5 is recommended.
· By default, no checksum is verified.
· It has been standardized under ISO/IEC 16388.
SDK Features:
· An optional mod43 checksum can be enforced.
· All ASCII characters including control characters encoding support can be enabled.
Specification of Code 39
Code 39 is sometimes used with an optional modulo 43 check digit. Using it requires this feature to be enabled in the barcode reader. The code with check digit is referred to as Code 39 mod 43.
To compute this, each character is assigned a value. The assignments are listed in the table above, and almost, but not quite, systematic.
Here is how to do the checksum calculation:
· Take the value (0 through 42) of each character in the barcode excluding start and stop codes.
· Sum the values.
· Divide the result by 43.
· The remainder is the value of the checksum character to be appended.
Code 93
Code 93 is a barcode symbology designed in 1982 by Intermec to provide a higher density and data security enhancement to Code 39. It is an alphanumeric, variable length symbology. Code 93 is used primarily by Canada Post to encode supplementary delivery information. Every symbol includes two check characters.
Each Code 93 character is nine modules wide, and always has three bars and three spaces, thus the name. Each bar and space is from 1 to 4 modules wide. (For comparison, a Code 39 character consists of five bars and five spaces, three of which are wide, for a total width of 13–16 modules.)
Code 93 is designed to encode the same 26 upper case letters, 10 digits and 7 special characters as code 39:
A B C
D E F G H I J K L M N O P Q R S T U V W X Y Z
0 1 2
3 4 5 6 7 8 9
- . $
/ + % SPACE
In addition to 43 characters, Code 93 defines 5 special characters (including a start/stop character), which can be combined with other characters to unambiguously represent all 128 ASCII characters.
In an open, the system, the minimum value of the X dimension is 7.5 miles (0.19 mm). The minimum bar height is 15 percent of the symbol length or 0.25 inches (6.4 mm), whichever is greater. The starting and trailing quiet zone should be at least 0.25 inches (6.4 mm).
Characteristics:
· Mostly used in logistics to encode application specific identifiers.
· Data in the standard encoding (numbers 0-9, capital letters A-Z, symbols -.$/+% and space) and Full ASCII mode (including control characters) are supported.
· Supports variable length data content.
· Two mod47 checksums are verified.
Specification of Code 93
A typical code 93 barcode has the following structure:
· A start character *
· Encoded message
· First modulo-47 check character "C"
· Second modulo-47 check character "K"
· Stop Character *
· Termination bar
Code 128
Code 128 is one of the most popular, highest-density linear barcodes, widely used in applications where a relatively large amount of data must be encoded in a relatively small amount of space. For the most part, Code 128 tends to replace Code 39 and Interleaved 2 of 5 as a more compact and flexible code for warehouse and distribution applications thanks to its continuous, self-checking bidirectional features. You will also find it commonly used in the health industry, blood banking and electronics manufacturer.
The name Code 128 stems from the fact that it encodes not only text, numbers and numerous functions but also the entire ASCII 128 character set. Another relatively unknown bit of trivia (or coincidence) about Code 128 is that was created back in the early 1980s by Ted Williams from Computer Identics (not of baseball fame) to meet the needs of the then-thriving printed circuit board industry.
A strong survivor amongst a multitude of early generation barcodes, Code 128 is classified as a variable length barcode. Every Code 128 barcode contains a start character, a string of data, a Modula or Mod 103 check digit and a stop character. The entire Code 128 offers a total of 107 different printed “patterns†(103 data symbols, 3 start codes and 1 stop code.)
Each barcode can, in turn, have one of three different meanings based on the specific Character Set used (A, B, or C) and initiated by one of the 3 start codes. Due to the complexity of the character sets, it even has the feature to automatically switch between character sets to best fit the label.
•128A – Contains ASCII characters 00-95 (0-9, A-Z plus control codes) and special characters
•128B – Contains ASCII characters 32-127 (0-9, A-Z, a-z) and special characters
•128C – Contains 00-99 (double density of numeric data only and FNC1.
•128 Auto – Encodes your data with the shortest number of bars automatically and should be used whenever possible
To recognize Code 128, each character in a Code 128 symbol begins with a bar and ends with a space (except for the stop character which adds an extra bar). Each is made up of three bars and three spaces. The bars and spaces have 4 different widths (1, 2, 3 or 4 units) with the sum of the bar widths being even and the sum of the spaces being odd for a total of 11 units per character.
Over time, Code 128 has been adapted with specific industry standards to handle complex product identification:
•GS1-128 (formerly UCC128 or EAN128) – established by the same an organization that controls UPC barcodes and which handles the SSCC-18 and SSCC-14 used for shipping containers
•AIAG – the Automotive Industry Action Group
•ISBT-128 – for blood products
•SSCC-18 – for shipping containers
•USPS – uses a basic Code 128 for delivery confirmations
•USPS – uses Code USPS-L-3216, a 24 digit label for tubs and sacks
Characteristics:
· Used in a wide range of applications.
· The barcode data can be encoded numerical data only or two different subsets of the ASCII table. Combinations of the three different modes can be used in a single code.
· Supports variable length data content.
· A mandatory checksum is verified.
· It has been standardized under ISO/IEC 15417.
SDK Features:
· GS1 codes are identified to signal that the application identifier is present (GS128).
Specification of Code 128
The special symbol FNC4 ("Function 4"), present only in code sets A and B, can be used to encode all the Latin-1 (ISO-8859-1) characters in a Code 128 barcode. The feature is not widely supported and is not used in GS128. When a single FNC4 is present in a string, the following symbol is converted to ASCII as usual, and then 128 is added to the ASCII value. (If the following symbol is a shift, then a second symbol will be used to obtain the character.) If two FNC4s are used consecutively then all following characters will be treated as such, up to the end of the string or another pair of FNC4s. Between the double FNC4s, a single FNC4 will be used to denote that the following character will be standard ASCII.
Code128 specifies a combination of 6 alternating bars and spaces (3 of each) for each symbol. Thus, each symbol begins with a bar and ends with space. In barcode fonts, the final bar is generally combined with the stop symbol to make a wider stop pattern. The following table details the widths associated with each bar and space for each symbol. The width of each bar or space may be 1, 2, 3 or 4 units (modules). Using the example above, an 'A' would be depicted with the pattern of 10100011000, or as widths 111323 in the tables below.
The widths value is derived by counting the length of each run of 1's then 0's in the pattern, starting from the left. There will always be 6 runs and the lengths of these 6 runs from the Widths value. For example, using the pattern 10100011000, the run lengths are 1 (digit 1), 1 (digit 0), 1 (digit 1), 3 (digit 0), 2 (digit 1), 3 (digit 0). Reporting just the lengths of each run gives 1, 1, 1, 3, 2, 3, thereby producing a widths value of 111323.
GS1 DATABAR
DataBar (formerly known as RSS or Reduced
Space Symbology) is a relatively new bar code symbology that was formally
adopted by the global supply chain in January 2011. The GS1 DataBar can carry
all 14 digits of a manufacture’s GTIN and is
more than 50% smaller than the currently used UPC and EAN symbols. This makes
it particularly useful for identifying small/hard-to-mark items such as produce
and pharmaceutical items. Additionally, the GS1 DataBar symbol can carry GS1
Application Identifiers which allow additional information such as serial
numbers, lot numbers, and expiration dates to be encoded.
The greater dimensional efficiency combined with
the ability to encode additional data opens the doors for creating trade
solutions that greater support product identification, traceability, quality
control, and more flexible coding for coupon applications.
Characteristics:
· Used to encode a Global Trade Identification Numbers (GTIN) along with variable additional information defined by application identifiers (AI). Examples are price, weight or expiry date.
· Valid application identifiers (AI) are defined in the GS1 specification.
· Supports variable length data content.
· Barcode data is verified by an implicit checksum.
· It does not require quiet zones around the barcode.
· It has been standardized under ISO/IEC 24724.
· DataBar-14 is supported in the omnidirectional, truncated and stacked flavor.
· DataBar Expanded is supported in the normal and stacked flavor.
· DataBar Limited is supported since SDK version 4.11.
Specification of GS1
DATABAR
· Databar bar code symbols can encode all 14 digits of a GTIN-14 were UPC & EAN cannot.
· The Databar symbol is over 50% smaller than EAN/UPC so it can be used for smaller or hard to mark items.
· Databar bar codes are not going to replace EAN/UPC symbols. Product manufacturers can decide the language they wish to use based on package design.
· Databar symbols and GS1 Application Identifiers will be available in all trade item scanning systems beginning January 1, 2010. At that time, retail POS scanners should be able to auto-discriminate between the various GS1 barcode languages.
· Adoption of the Databar symbology is critical to address the revised coupon coding requirements.
Types of DataBar barcodes
The GS1 DataBar family consists of seven symbols in total: four for use a point-of-sale and they're not for use at the point of sale. The symbols for use at point-of-sale are shown below.
|
DataBar Omnidirectional |
|
· USPS IMB Symbol ID: ]e0 · Capacity: 14 numeric · Omnidirectional · Supports GTIN, GCN · Does not support attributes |
|
DataBarStacked Omnidirectional |
|
· DataBarStacked Omnidirectional Symbol ID: ]e0 · Capacity: 14 numeric · Omnidirectional · Supports GTIN, GCN · Does not support attributes |
|
DataBar Expanded Stacked |
|
· Symbol ID: ]e0 · Capacity: Maximum 74 Numeric/ 41 alphabetic · Omnidirectional · Supports GTIN, GCN · Does support attributes |
|
DataBar Expanded |
|
· Symbol ID: ]e0 · Capacity: Maximum 74 Numeric/ 41 alphabetic · Omnidirectional · Supports GTIN, GCN · Does support attributes |
EAN Code
The International Article Number (also known as European Article Number or EAN,) is a standard describing a barcode symbology and numbering system used in global trade to identify a specific retail product type, in a specific packaging configuration, from a specific manufacturer. The standard has been subsumed in the Global Trade Item Number standard from the GS1 organization; the same numbers can be referred to as GTINs and can be encoded in other barcode symbologies defined by GS1. EAN barcodes are used worldwide for lookup at retail point of sale, but can also be used as numbers for other purposes such as wholesale ordering or accounting.
The most commonly used EAN standard is the thirteen-digit EAN-13, a superset of the original 12-digit Universal Product Code (UPC-A) standard developed in 1970 by George J. Laurer. An EAN-13 number includes a 3-digit GS1 prefix (indicating country of registration or a special type of product). A prefix with the first digit of "0" indicates a 12-digit UPC-A code follows. A prefix with the first two digits of "45" or "49" indicates a Japanese Article Number (JAN) follows.
The less commonly used 8-digit EAN-8 barcode was introduced for use on small packages, where EAN-13 would be too large. 2-digit EAN-2 and 5-digit EAN-5 are supplemental barcodes, placed on the right-hand side of EAN-13 or UPC. These are generally used for periodicals like magazines or books, to indicate the current year's issue number; and weighed products like food, to indicate the manufacturer's suggested retail price.
Characteristics:
· Used to encode Global Trade Identification Numbers (GTIN).
· Contains 8 (EAN-8) or 13 (EAN-13) numerical digits.
· The last digit serves as a mod10 checksum.
· Additional data can be stored in an EAN-2 or EAN-5 add-on code.
· It has been standardized under ISO/IEC 15420.
ISSN
(Used to identify periodicals around the world)
An International Standard Serial Number (ISSN) is an eight-digit serial number used to uniquely identify a serial publication. The ISSN is especially helpful in distinguishing between serials with the same title. ISSN is used in ordering, cataloging, interlibrary loans, and other practices in connection with serial literature.
The ISSN system was first drafted as an International Organization for Standardization (ISO) international standard in 1971 and published as ISO 3297 in 1975. ISO subcommittee TC 46/SC 9 is responsible for maintaining the standard.
ISSN and ISBN codes are similar in concept, where ISBNs are assigned to individual books. An ISBN might be assigned for particular issues of a serial, in addition to the ISSN code for the serial as a whole. An ISSN, unlike the ISBN code, is an anonymous identifier associated with a serial title, containing no information as to the publisher or its location. For this reason, a new ISSN is assigned to a serial each time it undergoes a major title change.
Since the ISSN applies to an entire serial a new identifier, the Serial Item and Contribution Identifier (SICI), was built on top of it to allow references to specific volumes, articles, or other identifiable components (like the table of contents).
There are two most popular media types that adopted special labels (indicating below in italics), and one, in fact, ISSN-variant, with also an optional label. All are used in standard metadata contexts like JATS, and the labels also, frequently, as abbreviations.
p-ISSN is a standard label for "Print ISSN", the ISSN for the print media (paper) version of a serial. Usually, it is the "default media", so the "default ISSN".
e-ISSN (or e-ISSN) is a standard label for "Electronic ISSN", the ISSN for the electronic media (online) version of a serial.
ISSN-L is a unique identifier for all versions of the serial containing the The same content across different media. As defined by ISO 3297:2007, the "linking ISSN (ISSN-L)" provides a mechanism for collocation or linking among the different media versions of the same continuing resource.
The ISSN-L is one ISSN number among the existing ISSNs, so, does not change the use or assignment of "ordinary" ISSNs; it is based on the ISSN of the first published medium version of the publication. If the print and online versions of the publication are published at the same time, the ISSN of the print version is chosen as the basis of the ISSN-L.
With ISSN-L is possible to designate one single ISSN for all those media versions of the title. The use of ISSN-L facilitates search, retrieval and delivery across all media versions for services like OpenURL, library catalogs, search engines or knowledge bases.
ISBN
The International Standard Book Number (ISBN) is a unique numeric commercial book identifier. Publishers purchase ISBNs from an affiliate of the International ISBN Agency.
An ISBN is assigned to each edition and variation (except reprinting) of a book. For example, an e-book, a paperback and a hardcover edition of the same book would each have a different ISBN. The ISBN is 13 digits long if assigned on or after 1 January 2007, and 10 digits long if assigned before 2007. The method of assigning an ISBN is nation-based and varies from country to country; often depending on how large the publishing industry is within a country.
The initial ISBN configuration of recognition was generated in 1967, based upon the 9-digit Standard Book Numbering (SBN) created in 1966. The 10-digit ISBN format was developed by the International Organization for Standardization (ISO) and was published in 1970 as international standard ISO 2108 (the SBN code can be converted to a ten-digit ISBN by prefixing it with a zero digit "0").
Privately published books sometimes appear without an ISBN. The International ISBN agency sometimes assigns such books ISBNs on its own initiative.
Another identifier, the International Standard Serial Number (ISSN), identifies periodical publications such as magazines; and the International Standard Music Number(ISMN) covers for musical scores.
The Standard Book Numbering (SBN) code is a 9-digit commercial book identifier system created by Gordon Foster, Emeritus Professor of Statistics at Trinity College, Dublin, for the booksellers and stationers WHSmith and others in 1965. The ISBN configuration of recognition was generated in 1967 in the United Kingdom by David Whitaker (regarded as the "Father of the ISBN") and in 1968 in the United States by Emery Koltay (who later became director of the U.S. ISBN agency R.R. Bowker).
The 10-digit ISBN format was developed by the International Organization for Standardization (ISO) and was published in 1970 as international standard ISO 2108. The United Kingdom continued to use the 9-digit SBN code until 1974. ISO has appointed the International ISBN Agency as the registration authority for ISBN worldwide and the ISBN Standard is developed under the control of ISO Technical Committee 46/Subcommittee 9 TC 46/SC 9. The ISO on-line facility only refers back to 1978.
An SBN may be converted to an ISBN by prefixing the digit "0". For example, the second edition of Mr. J. G. Reeder Returns, published by Hodder in 1965, has "SBN 340 01381 8" – 340 indicating the publisher, 01381 their serial number, and 8 being the check digit. This can be converted to ISBN 0-340-01381-8; the check digit does not need to be re-calculated.
Since 1 January 2007, ISBNs have contained 13 digits, a format that is compatible with "Bookland" European Article Number EAN-13s.
ISBN issuance is country-specific, in that ISBNs, are issued by the ISBN registration agency that is responsible for that country or territory regardless of the publication language. The ranges of ISBNs assigned to any particular country are based on the publishing profile of the country concerned, and so the ranges will vary depending on the number of books and the number, type, and size of publishers that are active. Some ISBN registration agencies are based in national libraries or within ministries of culture and thus may receive direct funding from the government to support their services. In other cases, the ISBN registration service is provided by organizations such as bibliographic data providers that are not government funded.
A full directory of ISBN agencies is available on the International ISBN Agency website. Partial listing:
· Australia: the commercial library services agency Thorpe-Bowker;
· Brazil: The National Library of Brazil
· Canada (English): Library and Archives Canada, a government agency
· Canada (French): Bibliothèque ET Archives Nationales du Québec
· Colombia: CámaraColombiana del Libro, an NGO
· Hong Kong: Books Registration Office (BRO), under the Hong Kong Public Libraries
· India: The Raja Rammohun Roy National Agency for ISBN (Book Promotion and Copyright Division), under the Department of Higher Education, a constituent of the Ministry of Human Resource Development
· Israel: Israel Center for Libraries
· Italy: ISER srl, owned by AssociazioneItalianaEditori (Italian Publishers Association)
· Maldives: The National Bureau of Classification (NBC)
· Malta: The National Book Council (Maltese: Il-Kunsill Nazzjonali tal-Ktieb)
· Morocco: The National Library of Morocco
· New Zealand: The National Library of New Zealand
· Pakistan: National Library of Pakistan
· Philippines: National Library of the Philippines
· South Africa: National Library of South Africa
· Turkey: General Directorate of Libraries and Publications, a branch of the Ministry of Culture
· The United Kingdom and Republic of Ireland: Nielsen Book Services Ltd, part of Nielsen Holdings N.V.
· United States: R.R. Bowker.
An EAN-8 is an EAN/UPC symbology barcode and is derived from the longer International Article Number (EAN-13) code. It was introduced for use on small packages where an EAN-13 barcode would be too large; for example on cigarettes, pencils, and chewing gum packets. It is encoded identically to the 12 digits of the UPC-A barcode, except that it has 4 (rather than 6) digits in each of the left and right halves.
EAN-8 barcodes may be used to encode GTIN-8 (8-digit Global Trade Identification Numbers) which are product identifiers from the GS1 System. A GTIN-8 begins with a 2- or 3-digit GS1 prefix (which is assigned to each national GS1 authority) followed by a 5- or 4-digit item reference element depending on the length of the GS1 prefix), and a checksum digit.
EAN-8 codes are common throughout the world, and companies may also use them to encode RCN-8 (8-digit Restricted Circulation Numbers), and use them to identify own-brand products sold only in their stores. RCN-8 are a subset of GTIN-8 which begin with the first digit of 0 or 2
This Symbology is also known as Japanese Article Number 13, JAN-13 Supplement 5/Five-digit Add-On, JAN-13 Supplement 2/Two-digit Add-On, JAN-13+5, JAN-13+2, JAN13, JAN13+5, JAN13+2
JAN-13 (Japanese Article Numbering) barcode Symbology is another name for EAN-13 barcode Symbology.
For JAN barcodes the first two digits must be 45 or 49 which identifies Japan.
The value to encode by JAN-13 has the following structure:
· 2 digits for Number System or Country Code which MUST BE 49 or 45
· 5 digits for Manufacturer (Company) Code or prefix
· 5 digits for Product Code
· 1 digit for checksum
Add-On or Supplement code
The Add-On Symbols were designed to encode information supplementary to that in the main bar code symbol on periodicals and paperback books. The Add-On can be composed of 2 or 5 digits only.
JAN (Japanese Article Numbering) is another name for the EAN-13 barcode. The first two digits - the country code - must be 45 or 49 (Japan).
The EAN 13, as the name suggests, represents a 13-character code. It uses 3 types of encodings: coding A, B and C. Of the 13 characters only 12 are represented since the first digit from the left identifies the sequence of encodings A or B of the next 6 characters. There are also start characters (101), stop (101) and central control (01010).
Composition:
101 (6 characters coded in A or B) 01010 (6 characters coded in C) 101
The printed code must have precise areas of offset and overflow to allow reading, and in particular, the thickness of 1 module between the code and the end of the label at the top, 1 module between the end of the numbers under the code and the end of the bottom plate, 7 modules between the code and the right margin and 11 modules for the left margin.
Therefore, an EAN 13 code will be made up of 11+ (12 * 7) + 7 + 3 + 3 + 5 = 113 modules, of which 95 code modules and 18 overflow modules.
EAN 13 is used for marking products for the global market:
· the first two digits of the code identify the country where the codification has been requested by who holds the product's trademark (for example, Italy is indicated by the digits 80 and 81);
· the next five digits identify the producer;
· the further five digits identify the name of the product within the company;
· the last digit represents the so-called " check digit ", which is calculated by means of a specific algorithm: the first 12 digits of the code are multiplied alternately by 1 and by 3, then the values ​​obtained are added; the check digit is the smallest number to add to this sum to get a multiple of 10. In the code example above, it is calculated as follows: 2 · 1 + 4 · 3 + 1 · 1 + 2 · 3 + 3 · 1 + 4 · 3 + 5 · 1 + 6 · 3 + 7 · 1 + 8 · 3 + 9 · 1 + 0 · 3 = 99; 1 is missing to reach the multiple of the nearest top 10, or 100.
How the 13-digit EAN-13 is encoded
The 13-digit EAN-13 number can be divided into 3 groups: first digit, left a group of 6 digits, right group of 6 digits.
The barcode consists of 95 equally spaced areas (also called modules). From left to right:
· 3 areas to encode the start marker.
· 42 (6*7) areas making up the left group of 6 digits. This can be further subdivided into 6 subgroups, each consisting of seven areas. The subgroups encode digits 2-7. Each of these encodings can have even or odd parity. The parties have taken together, indirectly encode the first digit of EAN-13.
· 5 areas to encode the marker for the center of the barcode.
· 42 (6*7) areas making up the right group of 6 digits. This can be further subdivided into 6 subgroups, each consisting of seven areas. The subgroups encode digits 8-13. Digits 8-13 are all encoded with even parity. Digit 13 is the check digit.
· 3 areas to encode the end marker.
Each area can be a black bar (1) or white space (0). A maximum of four black bar areas can be grouped together, these make up a wide black bar. Likewise, a maximum of four white space areas can be grouped together, these make up a wide white space.
The start marker and the end marker are encoded as 101. The center marker is encoded as 01010.
Each digit in EAN-13 (except digit 1, which is not directly encoded) consists of seven areas. A decimal digit is encoded so that it consists of two (wide) bars and two (wide) spaces.
The digits in the left group are encoded so that they always start with white space, and end with a black bar. The digits in the right group are encoded so that they always start with a black bar, and end with white space.
Finally, the combination of variable-width black bars and white spaces encode the EAN-13 number.
Introduction of Interleaved-Two-of-Five (ITF)
Code 25 Interleaved (also known as Code 2 of 5 Interleaved, Interleaved 2 or 5, or ITF) is a variant of Code 25 Industrial that stores data in pairs, with 5 bars representing one digit, and the 5 spaces interleaved within the bars representing the second digit. Thus, every 10 bar/spaces represent two digits (as compared to Code 25 Industrial, where every 10 bar/spaces represent a single digit). This limits Code 25 Interleaved to storing an even number of digits, but it is much more compact than Code 25 Industrial. When storing an odd number of digits, a leading zero is typically added, though some implementations use 5 narrow spaces as the last digit (which strictly speaking is not a valid 2 of 5 symbols since it does not include two wide modules). Here is the example from above; including a leading zero so there is an even number of digits:
In contrast to Code 25 Industrial, Code 25 Interleaved is a continuous barcode symbology; there is no inter-character space between adjacent data characters and the space between characters is part of the data representation.
Code 25 Interleaved uses unique start and stop characters, but does not include a check-digit. However, Code 25 Interleaved is self-checking (meaning, a single read/scan error will not result in incorrect decoding). Many users of Code 25 Interleaved still implements a check digit for added security and reliability. Here is the example again, diagramed for clarity:
Characteristics:
· It is used primarily in the distribution and warehouse industry.
· It encodes an even number of numerical characters.
· Supports variable length data content.
· Narrow to wide bar ratios from 1:2 up to 1:3 are supported. 1:2.5 is recommended.
· By default, no checksum is verified.
· It has been standardized under ISO/IEC 16390.
SDK Features:
· An optional mod10 checksum can be enforced.
Since Code 25 can only represent numeric digits, its uses are limited. The lack of a standardized check digit and its relatively low density further limit the barcode. Code 25 Industrial was used initially in the logistics industry, primarily on the cartons of some products (though it has since been displaced by Code 25 Interleaved).
With its higher data density and self-checking symbology, Code 25 Interleaved is used more commonly.
Code 25 (Interleaved in particular) is still in use today in several industries:
· The GS1 ITF-14 standard uses Code 25 Interleaved for carton labeling, where the cartons contain products which in turn are typically labeled with UPC or EAN barcodes.
· 135 film (35mm) canisters use a Code 25 Interleaved barcode which is scanned by many film-processing machines when the canister is inserted for developing.
· Deutsche Post (DHL) uses two variants of Code 25 Interleaved: Identcode and Leitcode.
Introduction of MSI Plessey
Today we’re going to take a look at the lesser-known MSI Plessey barcode symbology. MSI Plessey (or Modified Plessey) was developed by the MSI Data Corporation to serve as an evolution of the original Plessey barcode, which was created in the early 1970s. The original Plessey barcode was developed for the library industry, though today the MSI Plessey code is typically used for inventory management in retail environments. You will commonly find these codes marking the shelves in supermarkets.
Characteristics:
· MSI is used primarily for inventory control, marking storage containers and shelves in warehouse environments.
· Encodes any number of numerical characters.
· By default, a mod10 checksum is verified.
SDK Features:
· Verifying no checksum is supported as an option.
· Alternative supported checksum options are mod11, mod1010 and mod1110.
Character set and binary lookup
The MSI bar code represents only digits 0–9; it does not support letters or symbols.
Each digit is converted to 4 binary coded decimal bits. Then a 1 bit is prepended and two 0 bits are appended.
Finally, each bit is printed as a bar/space pair totaling three modules wide. A 0 bit is represented as 1/3 bar followed by 2/3 space, while a 1 bit is represented as 2/3 bar followed by 1/3 space.
Here’s an example:
As an example, we will generate an MSI barcode for the number sequence 1234567 using the most common Mod 10 check digit methodology.
The check digit (as calculated above) for this sequence is 4.
Once you have calculated your check digit, simply map each character in the string to be encoded using the table above as a reference to get the binary map of the bar code; remember to precede the code with "start" and to end it with "stop" For example, to map the string 1234567 with a Mod 10 check digit it would produce the following binary map:
|
Character |
Map |
Comment |
|
Start |
110 |
The start character |
|
1 |
100100100110 |
The number 1 |
|
2 |
100100110100 |
The number 2 |
|
3 |
100100110110 |
The number 3 |
|
4 |
100110100100 |
The number 4 |
|
5 |
100110100110 |
The number 5 |
|
6 |
100110110100 |
The number 6 |
|
7 |
100110110110 |
The number 7 |
|
4 |
100110100100 |
The check digit 4 |
|
Stop |
1001 |
This results in the following barcode:
Usage Filed
It is one of the first barcode symbology, and is still used in some rare libraries and for shelf tags in retail stores, in part as a solution to their internal requirement for stock control.
The Plessey was first used in the early 1970s by J.Sainsbury to identify all of its products on supermarket shelves for its product restocking system.
What is the Universal Product Code (UPC)?
A UPC, short for Universal Product Code, is a type of code printed on retail product packaging to aid in identifying a particular item. It consists of two parts – the machine-readable barcode, which is a series of unique black bars, and the unique 12-digit number beneath it.
The purpose of UPCs is to make it easy to identify product features, such as the brand name, item, size, and color, when an item is scanned at checkout. In fact, that’s why they were created in the first place – to speed up the checkout process at grocery stores. UPCs are also helpful in tracking inventory within a store or warehouse.
To obtain a UPC for use on a product a company has to first apply to become part of the system. GS1 US, the Global Standards Organization, formerly known as the Uniform Code Council, manages the assigning of UPCs within the US.
Characteristics:
· Used to encode Global Trade Identification Numbers (GTIN).
· Contains 6 (UPC-E) or 12 (UPC-A) numerical digits.
· The last digit serves as a mod10 checksum.
· Additional data can be stored in an EAN-2 or EAN-5 add-on code.
· It has been standardized under ISO/IEC 15420.
SDK Features:
· The first digit is always zero and can be removed on demand.
· UPC-E representation can be automatically converted to the UPC-A format.
Parts of a UPC
After paying a fee to join, GS1 assigns a 6-digit manufacturer identification number, which becomes the first six digits in the UPC on all the company’s products. That number identifies the particular manufacturer of the item.
The next five digits of the UPC is called an item number. It refers to the actual product itself. Within each company is a person responsible for issuing item numbers, to ensure that the same number isn’t used more than once and that old numbers referring to discontinued products are phased out.
Many consumer products have several variations, based on, for example, size, flavor, or color. Each variety requires its own item number. So a box of 24 one-inch nails has a different item number than a box of 24 two-inch nails or a box of 50 one-inch nails.
The last digit in the 12-digit UPC is called the check digit. It is the product of several calculations – adding and multiplying several digits in the code – to conform to the checkout scanner that the UPC is valid. If the check digit code is incorrect, the UPC won’t scan properly.
UPC-E is a compressed variation of the UPC-A symbol that is used where physical label space is limited. Compression works by squeezing out zeroes when printing the barcode and then re-inserting them automatically in the barcode scanner. It is important to understand that every UPC-E code can be de-compressed into its UPC-A equivalent, but not every UPC-A code can be compressed to UPC-E.
Since compression works by squeezing out zeroes, the original UPC-A code needs to have some spare zeroes, to begin with. Only manufacturer GS1 ID numbers beginning with zero are eligible (Number System 0). In addition, there are four rules that determine what UPC codes can be printed using the compressed UPC-E format:
UPC-A is used for marking products that are sold at retail in the USA. The barcode identifies the manufacturer and specific product so point-of-sale cash register systems can automatically look up the price. Note that the UPC-A and EAN-13 codes are valid worldwide, so products marked with a UPC-A code can be sold outside the USA. The UPC-A Code and the assignment of manufacturer ID numbers are administered by GS1.
The UPC-E code is a compressed barcode which is intended for use on physically small items. Compression works by squeezing extra zeroes out of the barcode and then automatically re-inserting them at the scanner. Only barcodes containing zeroes are candidates for the UPC-E symbol. GS1 is very stingy when it comes to handing out manufacturer ID numbers that are rich in zeroes; these are reserved manufacturers of products that have a genuine need for the UPC-E symbol. If you need a small symbol, tell GS1 when you apply for a manufacturer's ID number and be prepared to substantiate your need.
Advantages of UPCs
UPCs have a number of advantages to businesses and consumers. Because they make it possible for barcode scanners to immediately identify a product and its associated price, UPCs improve speed.
They improve efficiency and productivity, by eliminating the need to manually enter product information.
They also make it possible to track inventory much more accurately than hand counting, to know when more product is needed on retail shelves or in warehouses. Or when there is an issue with a particular product and consumers who purchased it need to be alerted or a recall issued, UPCs allow products to be tracked through production to distribution to retail stores and even into consumer homes.
All UPC numbers are assigned by GS1 – the Global Standards Organization, formerly known as the Uniform Code Council. Their website is very helpful and includes complete information to applying for and getting assigned UPCs. If you’re outside the US, visit here to find contact info for your location.
If you need UPC labels to sell your products or plan on reselling through large retailers (such as Walmart, Whole Foods, Kohl’s, Home Depot, CVS, Michaels, among many others), you will need to work with GS1 directly. You may also find that over time, the number of retailers forcing GS1 compliance for traceability requirements will increase.
The KIX Barcode
The KIX barcode (Klant index) has nothing to do with breakfast cereal but is used for mail sorting by the postal service of the Netherlands, Koninklijke TNT Post (Royal TNT Post). (If you use that "TNT" name as a launching point for jokes about blowing up post offices, you'll probably get a visit from government agents in the current political climate.)
This sort of bar code system is regarded as "four-state" because there are four types of bars, classified by the presence of ascenders and/or descenders. This sort of system is transcribable using DAFTnotation. These sorts of bar codes are used by a number of countries in their postal systems, though the specific symbologies by which they encode characters can vary. The KIX system encodes alphanumeric characters, and is a slight variant of the Royal Mail 4-State system, omitting the start and end symbols and checksum.
The KIX barcode (Klant index)
· Used for mail sorting by the postal service of the Netherlands, Koninklijke TNT Post (Royal TNT Post)
· Regarded as “four-state†because there are four types of bars, classified by presence of ascenders and/or descenders
· Transcribable using DAFT notation
· Used by a number of countries in their postal systems, though the specific symbologies by which they encode characters can vary
· Encodes alphanumeric characters, and is a slight variant of the Royal Mail 4-State system, omitting the start and end symbols and checksum.
RM4SCC
RM4SCC (Royal Mail 4-State Customer Code) is the name of the barcode character set based on the Royal Mail 4-State Bar Code symbology created by Royal Mail. The RM4SCC is used for the Royal Mail Cleanmail service. It enables UK postcodes as well as Delivery Point Suffixes (DPSs) to be easily read by a machine at high speed.
This barcode is known as CBC (Customer Bar Code) within Royal Mail.
PostNL uses a slightly modified version called KIX which stands for Klant index (Customer index); it differs from CBC in that it doesn't use the start and end symbols or the checksum separates the house number and suffixes with an X and is placed below the address. Singapore Post uses RM4SCC without alteration.
There are strict guidelines governing the usage of these barcodes, which allow for maximum readability by machines.
They can be used with Royal Mail's Cleanmail system, as an alternative to OCR readable fonts, to allow businesses to easily and cheaply send large quantities of letters.
RM4SCC
· Used by the Royal Mail for its Cleanmail service
· Enables the UK postcodes as well as Delivery Point Suffixes (DPSs) to be easily read by a machine at high speed
· There are strict guidelines governing the usage of these barcodes, which allow for maximum readability by machines
· Can be used with Royal Mail’s Cleanmail system as an alternative to OCR readable fonts
· Allows businesses to easily and cheaply send large quantities of letters
Each character is made up of 4 bars, 2 of which extend upward, and 2 of which extend downward. The combination of the top and bottom halves gives 36 possible symbols: 10 digits and 26 letters.
The RM4SCC barcode on the right consists of a start character, the postcode, the Delivery Point Suffix (DPS), a checksum character, and a stop character. The DPS is a two-character code ranging from 1A to 9T, with codes 9U to 9Z being accepted as default codes when no DPS has been allocated.
RM4SCC Structure
An RM4SCC barcode
consist of the following elements:
The left quiet zone, a start character, the postcode, the Delivery Point Suffix
(DPS), a checksum character, and a stop character, the right quiet zone. The
structure of RM4SCC is as below:
RM4SCC
Barcode Size Setting
As
for RM4SCC size setting, two properties should be your main concern: bar width
(i.e. X dimension) and image width.
If you want to create an RM4SCC barcode with a fixed image height, you can
adjust the image height in the property setting panel.
RM4SCC Data Encoding
Being
a postal barcode symbology, RM4SCC encodes:
· Numeric Digits 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
· Upper-case alphabets A-Z
· Open and close brackets ( ) or [ ] (only used as start/stop bars)
RM4SCC Barcode Checksum Digit
RM4SCC barcode requires a module 6 checksum digit, but you don't need to worry about the complicated calculation, because of OnBarcode RM4SCC barcode generator software & components will automatically add checksum digit for you so your generated RM4SCC barcodes can be specification compatible and scannable.




{kind=link}